The Piemonte dataset example
Elias T Krainski
Started in 2022. Last update: Fri 10 Apr, 2026
Source:vignettes/web/piemonte.Rmd
piemonte.RmdAbstract
In this vignette we illustrate how to fit some of the spacetime models in Lindgren et al. (2024), see [SORT vol. 48, no. 1, pp. 3-66] and the related code, for the data analysed in Cameletti et al. (2013). To perform this we will use the Bayesian paradigm with theINLA package, using the features provided by the inlabru package to facilitate the coding.
Introduction
The packages and setup
We start loading the required packages and those for doing the visualizations, the ggplot2 and patchwork packages.
library(ggplot2)
library(patchwork)
library(INLA)
#> Loading required package: Matrix
#>
library(INLAspacetime)
#> see more at https://eliaskrainski.github.io/INLAspacetime
library(inlabru)
#> Loading required package: fmesher
library(fmesher)We will ask it to return the WAIC, DIC and CPO
ctrc <- list(
waic = TRUE,
dic = TRUE,
cpo = TRUE)Getting the dataset
We will use the dataset analysed in Cameletti et al. (2013), that can be downloaded as follows. First, we set the filenames
u0 <- paste0(
"http://inla.r-inla-download.org/",
"r-inla.org/case-studies/Cameletti2012/")
coofl <- "coordinates.csv"
datafl <- "Piemonte_data_byday.csv"
bordersfl <- "Piemonte_borders.csv"Download and read the borders file
### get the domain borders
if(!file.exists(bordersfl))
download.file(paste0(u0, bordersfl), bordersfl)
dim(pborders <- read.csv(bordersfl))
#> [1] 27821 2Download and read the coordinates file
### get the coordinates
if(!file.exists(coofl))
download.file(paste0(u0, coofl), coofl)
dim(locs <- read.csv(coofl))
#> [1] 24 3Download and read the dataset
### get the dataset
if(!file.exists(datafl))
download.file(paste0(u0, datafl), datafl)
dim(pdata <- read.csv(datafl))
#> [1] 4368 11Inspect the dataset
head(pdata)
#> Station.ID Date A UTMX UTMY WS TEMP HMIX PREC EMI PM10
#> 1 1 01/10/05 95.2 469.45 4972.85 0.90 288.81 1294.6 0 26.05 28
#> 2 2 01/10/05 164.1 423.48 4950.69 0.82 288.67 1139.8 0 18.74 22
#> 3 3 01/10/05 242.9 490.71 4948.86 0.96 287.44 1404.0 0 6.28 17
#> 4 4 01/10/05 149.9 437.36 4973.34 1.17 288.63 1042.4 0 29.35 25
#> 5 5 01/10/05 405.0 426.44 5045.66 0.60 287.63 1038.7 0 32.19 20
#> 6 6 01/10/05 257.5 394.60 5001.18 1.02 288.59 1048.3 0 34.24 41Prepare the time to be used
range(pdata$Date <- as.Date(pdata$Date, "%d/%m/%y"))
#> [1] "2005-10-01" "2006-03-31"
pdata$time <- as.integer(difftime(
pdata$Date, min(pdata$Date), units = "days")) + 1Standardize the covariates that will be used in the data analysis and
define a dataset including the needed information where the outcome is
the log of PM10, as used in Cameletti et al. (2013).
### prepare the covariates
xnames <- c("A", "WS", "TEMP", "HMIX", "PREC", "EMI")
xmean <- colMeans(pdata[, xnames])
xsd <- sapply(pdata[xnames], sd)
### prepare the data (st loc, scale covariates and log PM10)
dataf <- data.frame(pdata[c("UTMX", "UTMY", "time")],
scale(pdata[xnames], xmean, xsd),
y = log(pdata$PM10))
str(dataf)
#> 'data.frame': 4368 obs. of 10 variables:
#> $ UTMX: num 469 423 491 437 426 ...
#> $ UTMY: num 4973 4951 4949 4973 5046 ...
#> $ time: num 1 1 1 1 1 1 1 1 1 1 ...
#> $ A : num -1.3956 -0.7564 -0.0254 -0.8881 1.4785 ...
#> $ WS : num -0.0777 -0.2319 0.038 0.4429 -0.6561 ...
#> $ TEMP: num 2.1 2.07 1.82 2.06 1.86 ...
#> $ HMIX: num 2.18 1.69 2.53 1.38 1.37 ...
#> $ PREC: num -0.29 -0.29 -0.29 -0.29 -0.29 ...
#> $ EMI : num -0.1753 -0.3454 -0.6353 -0.0985 -0.0324 ...
#> $ y : num 3.33 3.09 2.83 3.22 3 ...The data model definition
We consider the following linear mixed model for the outcome where are fixed effects, or regression coefficients including the intercept, for the matrix of covariates , is the spatio-temporal random effect having the matrix the projector matrix from the discretized domain to the data. The spatio-temporal random effect is defined in a continuous spacetime domain being discretized considering meshes over time and space. The difference from Cameletti et al. (2013) is that we now use the models in Lindgren et al. (2024) for .
Define a temporal mesh, with each knot spaced by h,
where h = 1 means one per day.
nt <- max(pdata$time)
h <- 1
tmesh <- fm_mesh_1d(
loc = seq(1, nt + h/2, h),
degree = 1)
tmesh$n
#> [1] 182Define a spatial mesh, the same used in Cameletti et al. (2013).
smesh <- fm_mesh_2d(
cbind(locs[,2], locs[,3]),
loc.domain = pborders,
max.edge = c(50, 300),
offset = c(10, 140),
cutoff = 5,
min.angle = c(26, 21))
smesh$n
#> [1] 142Visualize the spatial mesh, the border and the locations.
par(mfrow = c(1,1), mar = c(0,0,1,0))
plot(smesh, asp = 1)
lines(pborders, lwd = 2, col = "green4")
points(locs[, 2:3], pch = 19, col = "blue")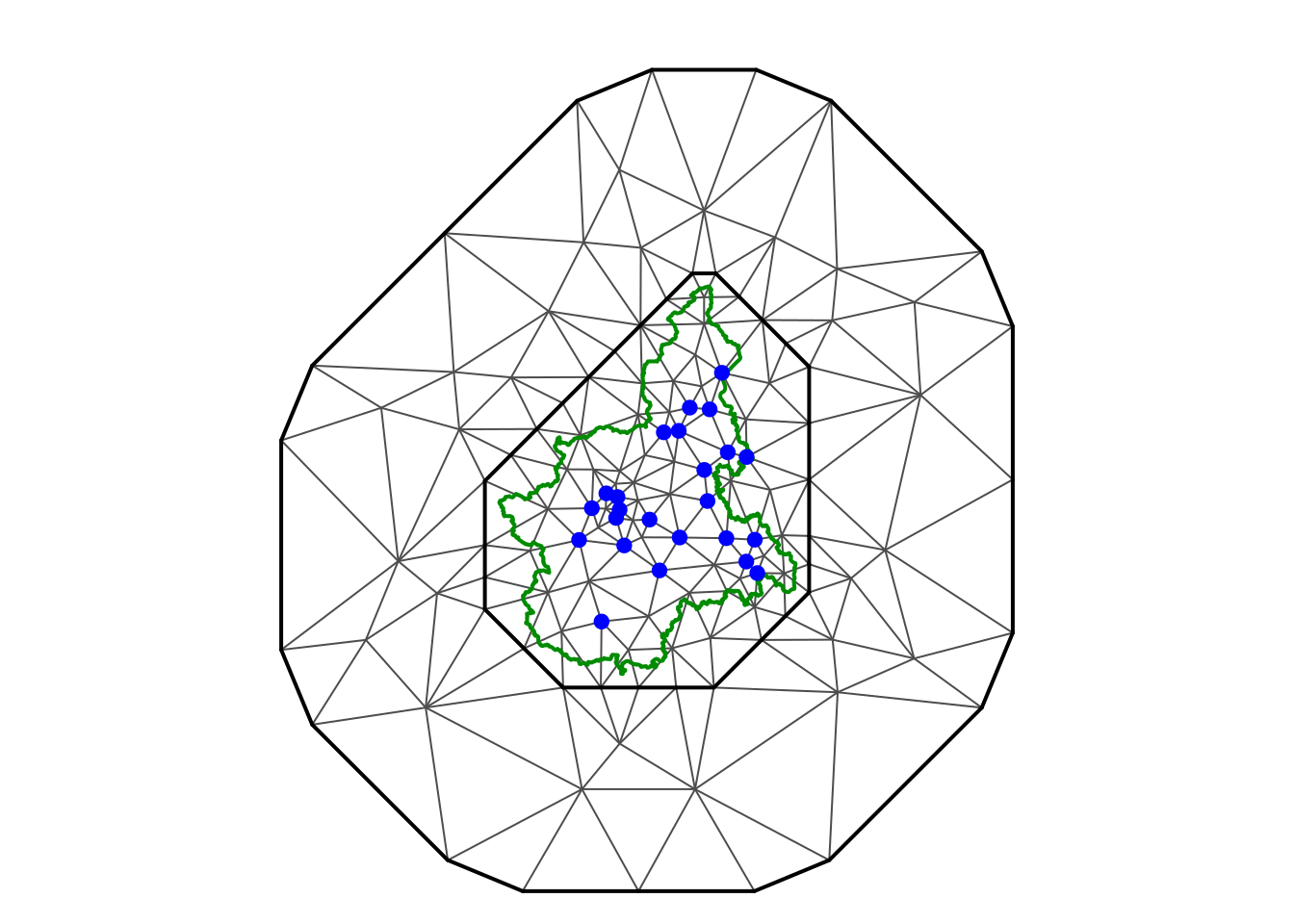
We set the prior for the likelihood precision considering a PC-prior, Simpson et al. (2017), through the following probabilistic statements: P() = , using = 1 and .
With inlabru we can define the likelihood model with
the like() function and use it for fitting models with
different linear predictors later.
lhood <- like(
formula = y ~ .,
family = "gaussian",
control.family = list(
hyper = lkprec),
data = dataf)The linear predictor, the right-rand side of the formula, can be defined using the same expression for of the both models that we are going to fit and is
The spacetime models
The implementation of the spacetime model uses the
cgeneric interface in INLA, see its
documentation for details. Therefore we have a C code to
mainly build the precision matrix and compute the model parameter priors
and compiled as static library. We have this code included in the
INLAspacetime package but it is also being copied to
the INLA package and compiled with the same compilers
in order to avoid possible mismatches. In order to use it, we have to
define the matrices and vectors needed, including the prior parameter
definitions.
The class of models in Lindgren et al. (2024) have the spatial range, temporal range and marginal standard deviation as parameters. We consider the PC-prior, as in Fuglstad et al. (2017), for these parameters defined from the probability statements: P()=, P()= and P()=. We consider , and .
The selection of one of the models in Lindgren et al. (2024) is by chosing the , and as integer numbers. We will start considering the model , and , which is a model with separable spatio-temporal covariance, and then we fit some of the other models later.
Defining a particular model
We define an object with the needed use the function
stModel.define() where the model is selected considering
the values for
,
and
collapsed. In order to illustrate how it is done, we can set an overall
integrate-to-zero constraint, which is not need but helps model
components identification. It uses the weights based on the mesh node
volumes, from both the temporal and spatial meshes. This can be set
automatically when defining the model by adding
constr = TRUE.
model <- "102"
stmodel <- stModel.define(
smesh, tmesh, model,
control.priors = list(
prs = c(150, 0.05),
prt = c(10, 0.05),
psigma = c(5, 0.05)),
constr = TRUE)Initial values for the hyper-parameters help to fit the models in less computing time. It is also important to consider in the light that each dataset has its own parameter scale. For example, we have to consider that the spatial domain within a box of around by kilometers, which we already did when building the mesh and setting the prior for or .
We can set initial values for the log of the parameters so that it would take less iterations to converge:
theta.ini <- c(4, 7, 7, 1)The code to fit the model through inlabru is
fit102 <-
bru(M,
lhood,
options = list(
control.mode = list(theta = theta.ini, restart = TRUE),
control.compute = ctrc))Summary of the posterior marginal distributions for the fixed effects
fit102$summary.fixed[, c(1, 2, 3, 5)]
#> mean sd 0.025quant 0.975quant
#> Intercept 3.73691498 0.246460370 3.250580850 4.222912212
#> A -0.17939135 0.050043273 -0.278588362 -0.081312832
#> WS -0.06043117 0.008441202 -0.076973667 -0.043867080
#> TEMP -0.12241442 0.035186071 -0.191482383 -0.053481411
#> HMIX -0.02373352 0.013204023 -0.049587997 0.002198773
#> PREC -0.05355344 0.008606374 -0.070415404 -0.036660633
#> EMI 0.03628541 0.015196730 0.006121124 0.065804989For the hyperparameters, we transform the posterior marginal distributions for the model hyperparameters from the ones computed in internal scale, , , and , to the user scale parametrization, , , and , respectivelly.
post.h <- list(
sigma_e = inla.tmarginal(function(x) exp(-x/2),
fit102$internal.marginals.hyperpar[[1]]),
range_s = inla.tmarginal(function(x) exp(x),
fit102$internal.marginals.hyperpar[[2]]),
range_t = inla.tmarginal(function(x) exp(x),
fit102$internal.marginals.hyperpar[[3]]),
sigma_u = inla.tmarginal(function(x) exp(x),
fit102$internal.marginals.hyperpar[[4]])
)Then we compute and show the summary of it
shyper <- t(sapply(post.h, function(m)
unlist(inla.zmarginal(m, silent = TRUE))))
shyper[, c(1, 2, 3, 7)]
#> mean sd quant0.025 quant0.975
#> sigma_e 0.1810131 0.003770221 0.1737355 0.1885424
#> range_s 280.6525331 17.042490359 248.8005475 315.7147834
#> range_t 49.8996934 8.160995550 36.0112571 67.9911649
#> sigma_u 1.1369314 0.087355078 0.9772896 1.3201757However, it is better to look at the posterior marginal itself, and we will visualize it later.
The model fitted in Cameletti et al. (2013) includes two more covariates and setup a model for discrete temporal domain where the temporal correlation is modeled as a first order autoregression with parameter . In the fitted model here is defined considering continuous temporal domain with the range parameter . However, the first order autocorrelation could be taken as , where is the temporal resolution used in the temporal mesh and is equal for the fitted model. We can compare ou results with Table 3 in Cameletti et al. (2013) with
Comparing different models
We now fit the model for as well, we use the same code for building the model matrices
model <- "121"
stmodel <- stModel.define(
smesh, tmesh, model,
control.priors = list(
prs = c(150, 0.05),
prt = c(10, 0.05),
psigma = c(5, 0.05)),
constr = TRUE)and use the same code for fitting as follows
fit121 <-
bru(M,
lhood,
options = list(
control.mode = list(theta = theta.ini, restart = TRUE),
control.compute = ctrc))We will join these fits into a list object to make it easier working with it
results <- list("u102" = fit102, "u121" = fit121)The computing time for each model fit
sapply(results, function(r) r$cpu.used)
#> u102 u121
#> Pre 0.680485 0.2633564
#> Running 137.280957 235.0718191
#> Post 3.430274 2.3039808
#> Total 141.391716 237.6391563and the number of fn-calls during the optimization are
sapply(results, function(r) r$misc$nfunc)
#> u102 u121
#> 327 370The posterior mode for each parameter in each model (in internal scale) are
sapply(results, function(r) r$mode$theta)
#> u102 u121
#> Log precision for the Gaussian observations 3.4192453 3.592748
#> Theta1 for field 5.6341273 7.290315
#> Theta2 for field 3.8867220 10.979673
#> Theta3 for field 0.1210873 2.153899We compute the posterior marginal distribution for the hyper-parameters in the user-interpretable scale, like we did before for the first model, with
posts.h2 <- lapply(1:2, function(m) vector("list", 4L))
for(m in 1:2) {
posts.h2[[m]]$sigma_e =
data.frame(
parameter = "sigma_e",
inla.tmarginal(
function(x) exp(-x/2),
results[[m]]$internal.marginals.hyperpar[[1]]))
for(p in 2:4) {
posts.h2[[m]][[p]] <-
data.frame(
parameter = c(NA, "range_s", "range_t", "sigma_u")[p],
inla.tmarginal(
function(x) exp(x),
results[[m]]$internal.marginals.hyperpar[[p]])
)
}
}Join these all to make visualization easier
posts.df <- rbind(
data.frame(model = "102", do.call(rbind, posts.h2[[1]])),
data.frame(model = "121", do.call(rbind, posts.h2[[2]]))
)
ggplot(posts.df) +
geom_line(aes(x = x, y = y, group = model, color = model)) +
ylab("Density") + xlab("") +
facet_wrap(~parameter, scales = "free")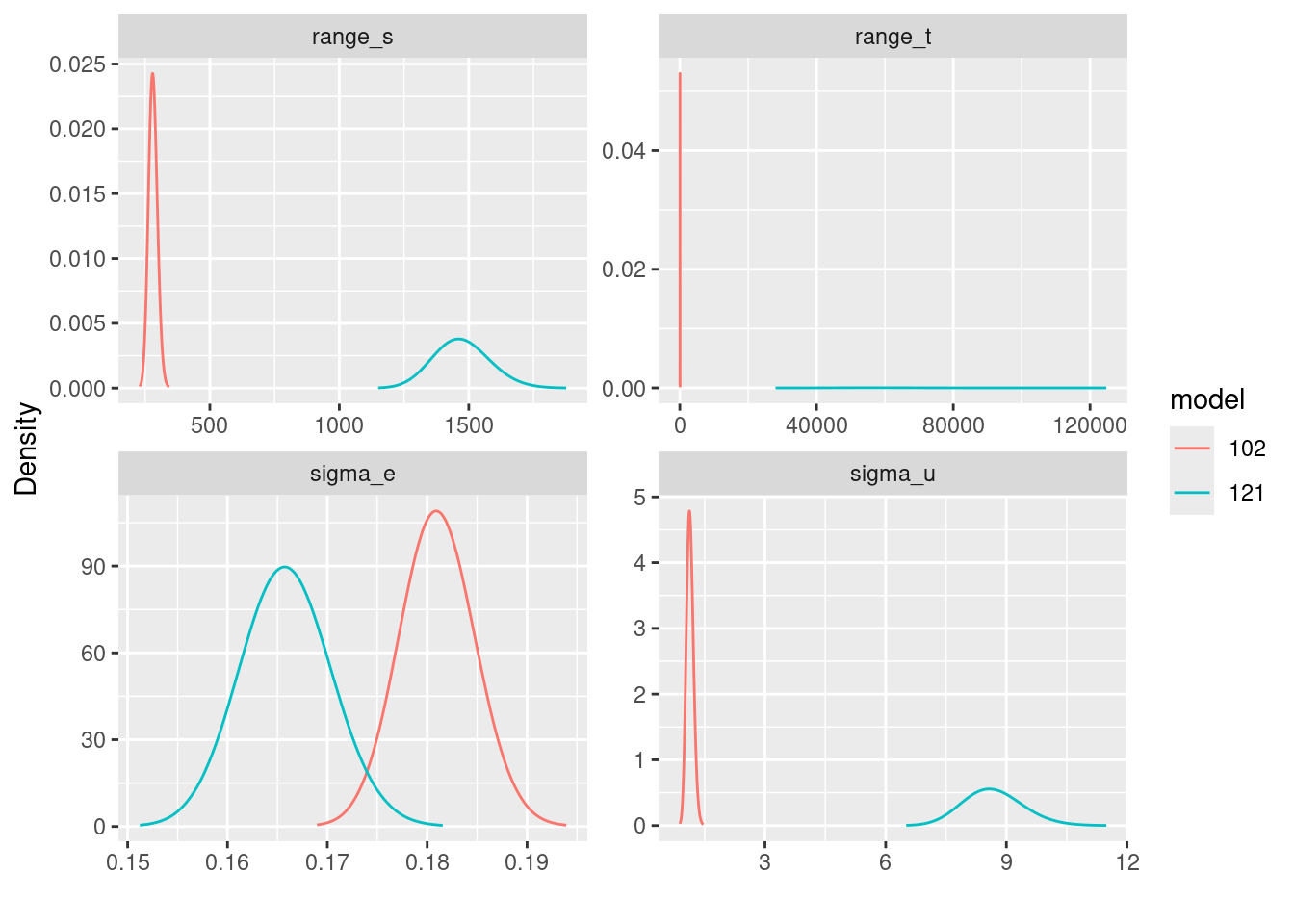
The comparison of the model parameters of for different models have to be done in light with the covariance functions as illustrated in Lindgren et al. (2024). The fitted by the different models are comparable and we can see that when considering model for , its posterior marginal are concentrated in values lower than when considering model .
We can look at the posterior mean of from both models and see that under model ‘121’ there is a wider spread.
par(mfrow = c(1, 1), mar = c(3, 3, 0, 0.0), mgp = c(2, 1, 0))
uu.hist <- lapply(results, function(r)
hist(r$summary.random$field$mean,
-60:60/20, plot = FALSE))
ylm <- range(uu.hist[[1]]$count, uu.hist[[2]]$count)
plot(uu.hist[[1]], ylim = ylm,
col = rgb(1, 0.1, 0.1, 1.0), border = FALSE,
xlab = "u", main = "")
plot(uu.hist[[2]], add = TRUE, col = rgb(0.1, 0.1, 1, 0.5), border = FALSE)
legend("topleft", c("separable", "non-separable"),
fill = rgb(c(1,0.1), 0.1, c(0.1, 1), c(1, 0.5)),
border = 'transparent', bty = "n")
We can also check fitting statistics such as DIC, WAIC, the negative of the log of the probability ordinates (LPO) and its cross-validated version (LCPO), summarized as the mean.
t(sapply(results, function(r) {
c(DIC = mean(r$dic$local.dic, na.rm = TRUE),
WAIC = mean(r$waic$local.waic, na.rm = TRUE),
LPO = -mean(log(r$po$po), na.rm = TRUE),
LCPO = -mean(log(r$cpo$cpo), na.rm = TRUE))
}))
#> DIC WAIC LPO LCPO
#> u102 -0.3767749 -0.2595259 -0.4053154 -0.1173962
#> u121 -0.4110288 -0.3525654 -0.5079108 -0.1157926The automatic group-leave-out cross validation
One may be interested in evaluating the model prediction. The leave-one-out strategy was already available in INLA since several years ago, see Held, Schrodle, and Rue (2010) for details. Recently, an automatic group cross validation strategy was implemented, see Liu and Rue (2023) for details.
g5cv <- lapply(
results, inla.group.cv, num.level.sets = 5,
strategy = "posterior", size.max = 50)We can inspect the detected observations that have the posterior linear predictor correlated with each one, including itself. For 100th observation under model “102” we have
g5cv$u102$group[[100]]
#> $idx
#> [1] 52 76 98 100 106 124
#>
#> $corr
#> [1] 0.2577538 0.4291309 0.3004975 1.0000000 0.3299912 0.4291309and for the result under model “121” we have
g5cv$u121$group[[100]]
#> $idx
#> [1] 52 76 98 100 124 148
#>
#> $corr
#> [1] 0.1661419 0.3728247 0.1661419 1.0000000 0.3751859 0.1621502which has intersection but are not the same, for the model setup used.
We can check which are these observations in the dataset
dataf[g5cv$u102$group[[100]]$idx, ]
#> UTMX UTMY time A WS TEMP HMIX PREC
#> 52 437.36 4973.34 3 -0.8881265 0.982687762 1.077344 -0.6959771 1.94505331
#> 76 437.36 4973.34 4 -0.8881265 0.674216318 1.297701 0.9479287 3.70037355
#> 98 423.48 4950.69 5 -0.7563919 -0.578948923 1.387847 -0.4413098 0.08590275
#> 100 437.36 4973.34 5 -0.8881265 0.770613644 1.441935 0.2530248 0.16426526
#> 106 416.65 4985.65 5 0.3225334 -0.000564966 1.397863 1.1608209 0.63052220
#> 124 437.36 4973.34 6 -0.8881265 0.751334179 1.618220 1.0845756 0.03692618
#> EMI y
#> 52 -0.01821338 2.564949
#> 76 -0.01542101 2.708050
#> 98 -0.27115486 2.484907
#> 100 0.01622576 2.890372
#> 106 -0.61950205 2.708050
#> 124 0.02599903 2.995732and found that most are at the same locations in nearby time.
We can compute the negative of the mean of the log score so that lower number is better